操控448个原子:通往容错量子计算的“恒定熵”架构
产业动态 | 发布时间:2025-11-24 | 阅读:540 次2025年11月,哈佛大学、麻省理工学院等机构的研究人员报道了一种可扩展且具有容错能力的中性原子量子计算新架构。该团队利用一个包含多达448个中性原子的可重构阵列,成功展示了通往实用化量子计算机的两大核心技术支柱:首先是实现了“低于阈值”的量子纠错,证明了在大规模原子体系中抑制错误的可行性;其次,构建了能够在“恒定熵”下运行的深度逻辑电路,展示了通用量子计算的可扩展性。这项工作不仅是中性原子量子计算体系的一个巨大飞跃,更为构建真正实用的容错量子计算机提供了一份清晰的蓝图。相关论文于11月 10 日在线发表在国际学术期刊《自然》[Nature (2025)]。

亮点小结
· 在实验中展示了可拓展通用量子计算的核心技术并探索了容错量子计算向更深线路层数迈进的核心机制。
· 将之前基于“自旋-丢失”转换实现的破坏性测量升级为基于“自旋-位置”转换实现的非破坏性测量,结合线路中初始化实现了比特复用,将实验重复速率提高了两个数量级。
· 将“比特丢失”信息加入解码器,优化了低于纠错阈值情况下解码器的表现。
· 使用量子隐形传态(teleportation)来实现横向门(Transversal gate),由此便可通过比特复用来降低额外开销。
关键性能
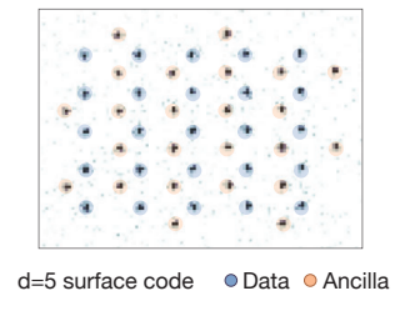
实验平台:基于铷原子的四区可编程架构
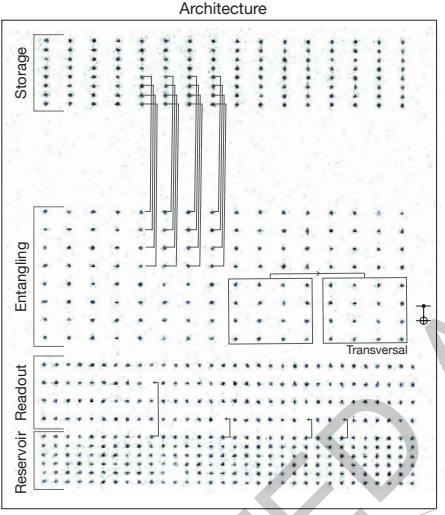
这项工作的物理实现平台,是一个由数百个中性87Rb(铷)原子构成的可编程量子比特阵列。整个阵列的控制依赖于激光的精密操控,通过激光冷却技术获得超冷的原子云,然后使用光镊来俘获与控制单个原子,每个原子代表一个物理量子比特。系统依赖两套关键工具协同:一个空间光调制器(SLM)生成静态的光阱阵列主体,以及一套声光偏转器(AOD)生成可移动的光镊。正是依靠这套AOD光镊,原子才得以在不同区域之间输运,执行复杂的操控和分区计算。整个处理器被精巧地划分为四个功能区域:准备区(Reservoir) 存储备用原子;存储区(Storage) 进行原子初始化和排列;纠缠区(Entangling Zone) 是核心计算区域,通过里德堡激光执行关键的两比特逻辑门操作;读出区(Readout Zone) 用于读取计算结果或量子纠错所需的错误信息。原子的装载、填补和在区域间的输运,构成了一个支持容错计算的循环流程。
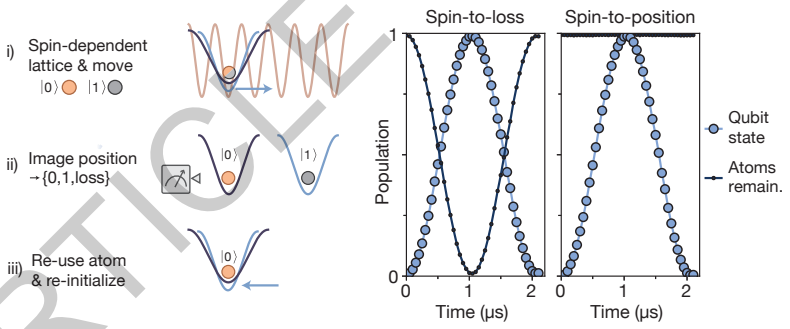
核心技术:非破坏性“自旋-位置”读出与擦除检测
在量子纠错中,系统需要频繁测量辅助比特以实时发现错误,但传统的测量方法常常是破坏性的,会消耗原子。该平台最大的技术突破之一,是实现了一种非破坏性、自旋分辨的读出技术,它将原子的“自旋信息”转化为了“位置信息”。在读出区,系统结合了激光冷却技术,确保原子在测量过程中能保持极低的温度,抑制荧光加热导致的原子损失。
该过程在原子被移动到“读出区”时进行:系统开启一束态选择性的一维光晶格激光。这束光晶格将处于自旋1态的原子牢牢束缚在原地;而对处于自旋0态的原子则几乎没有作用力。随后,可移动光镊将处于自旋0态的原子平移到一个新的位置。通过随后同时成像,自旋信息便转化成了空间位置信息。更关键的是,如果在两个预定位置都没有探测到荧光,则被无歧义地判读为“原子丢失”错误(即“擦除错误”)。这项技术不仅保留了原子供后续重用并分辨了自旋,而且对原子丢失错误的准确识别,极大地提升了纠错解码器的性能,使研究人员能够利用宝贵的“擦除信息”显著提升纠错成功率。
容错计算的实时挑战与解码创新
量子纠错(QEC)的有效性不仅取决于物理编码本身,还高度依赖于解码器的实时性和准确性。在实际的容错架构中,对错误症结(Syndrome)的测量需要快速、反复进行,以实时跟踪并抑制不断涌现的物理错误。这对数据处理提出了极高的实时性要求:解码器必须在极短的时间内从海量的测量数据中推断出最有可能的错误类型和位置。如果解码速度过慢,错误积累的速度将超过纠错速度,使整个 QEC 机制失效。
为应对这一严苛的计算挑战,研究团队在软件和算法层面进行了重大创新。他们采用了融合擦除信息(即原子丢失检测结果)的最概然(MLE)解码器,以及先进的机器学习(ML)解码器,这极大地提升了容错性能。为了满足实时计算的严苛要求,研究团队利用高性能 GPU(NVIDIA-A100)进行加速推理,使得每次解码的推断时间极短,确保了纠错的速度能够跟上错误的生成速度。实验证明,这一创新的解码策略,结合非破坏性读出的硬件优势,使纠错性能额外提高了1.73倍。此外,硬件上的创新也包括对原子进行线路中初始化的能力,将整个实验循环速率提高了两个数量级,为进行超深度的量子电路和快速、持续的 QEC 提供了坚实的硬件基础。
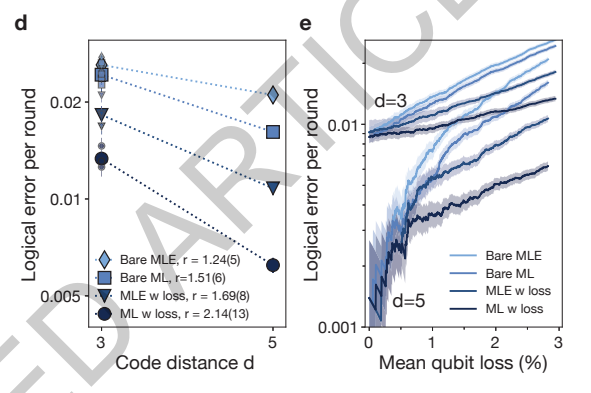
实验演示:实现容错计算的关键里程碑
研究团队通过量子纠错基准测试,验证了原子阵列容错运算的理论基础。他们构建 d=5 表面码模型:核心数据原子固定于 “纠缠区”,辅助原子块初始化后移入阵隙;里德堡激光使两者纠缠并编码错误信息,辅助原子块再移至 “读出区” 完成非破坏性测量。多轮 QEC 循环后,d=5 逻辑比特错误率比 d=3 低 2.14 倍,证实中性原子体系 “低于阈值” 性能,验证了物理资源提升逻辑比特可靠性的有效性;结合 “丢失检测” 与机器学习解码器,纠错性能再升 1.73 倍。
但 “低于阈值” 仅是容错起点,深度算法运行中,物理错误积累会导致 “熵积累” 与逻辑比特失效。团队提出基于量子隐形传态的 A-B 块交替架构:将计算逻辑转化为 A、B 两组逻辑数据块的交替传输,一个周期内先让携带当前信息的 A 组与低熵重置的 B 组纠缠,再测量 A 组 —— 此过程通过量子隐形传态,在完成逻辑门操作的同时,将纯逻辑信息精准转移至 B 组,且 A 组积累的物理错误与熵完全不传递给 B 组,A 组后续经重置恢复低熵状态。实验通过该架构成功运行 27 层逻辑电路,证明错误率和熵始终恒定,实现 “恒定熵” 可扩展架构。此外,原子复用技术使循环速率提升两个数量级,实现任意角度旋转,奠定通用量子计算基础。
展望:通往实用化量子计算的坚实一步
这项工作是重要里程碑,它系统整合中性原子系统在高量子比特数、灵活阵列重构及强纠缠机制的优势,构建完整容错架构。实验不仅证实 “低于阈值” 性能与 “恒定熵” 操作的可行性,还揭示容错设计关键原理,包括量子逻辑操作与熵去除的平衡,以及逻辑隐形传态在通用性与错误清除中的核心作用。
然而,从当前实验性能到实用化量子计算仍存挑战。当前实验性能仅达到阈值下的较低水平,而实现实用化所需的极低错误率,还需将性能大幅提升数倍,这要求从物理层面进行多方面优化:一是进一步提高单比特操作的保真度,需通过改进拉曼激光相关参数与校准流程实现;二是显著降低两比特纠缠门(如 CZ 门)的错误率,需提升里德堡激光功率以缩短门操作时间,同时改善真空环境、优化原子移动路径,并延长量子比特的相干时间。
软件与架构层面,挑战聚焦可扩展性与速度。虽 GPU 加速的机器学习解码器满足实时性,但训练过程及高编码距离适应性未充分验证;“恒定熵” 架构减少 QEC 轮数,可原子阵列操作速度(如逻辑隐形传态周期)比超导量子比特慢 10-20 倍,需优化原子移动、测量及重初始化以提升时钟频率。此外,需整合连续原子重装载技术,突破电路深度受备用原子数量的限制,实现长时间容错操作。
综上,该工作是中性原子体系容错量子计算研究的重要进展。未来通过硬件升级与算法优化,有望推动从“低于阈值”迈向“具备算法优势”的实用化阶段。
参考资料:
[1] A fault-tolerant neutral-atom architecture for universal quantum computation | Nature: https://www.nature.com/articles/s41586-025-09848-5
[2] A potential quantum leap — Harvard Gazette: https://news.harvard.edu/gazette/story/2025/11/a-potential-quantum-leap/
信息来源:“量子科话”微信公众号